Context rot is when an AI model gets worse the more you feed it. The text it needs is usually still sitting right there in the prompt. The model just loses the thread in all the extra words around it. You have probably watched it happen. A long chat that slowly drifts off the rails. A coding assistant that nails the first hour and then starts forgetting code it wrote itself twenty minutes ago. The blunt version is that more context does not always mean better answers, and past a certain point it means worse ones.
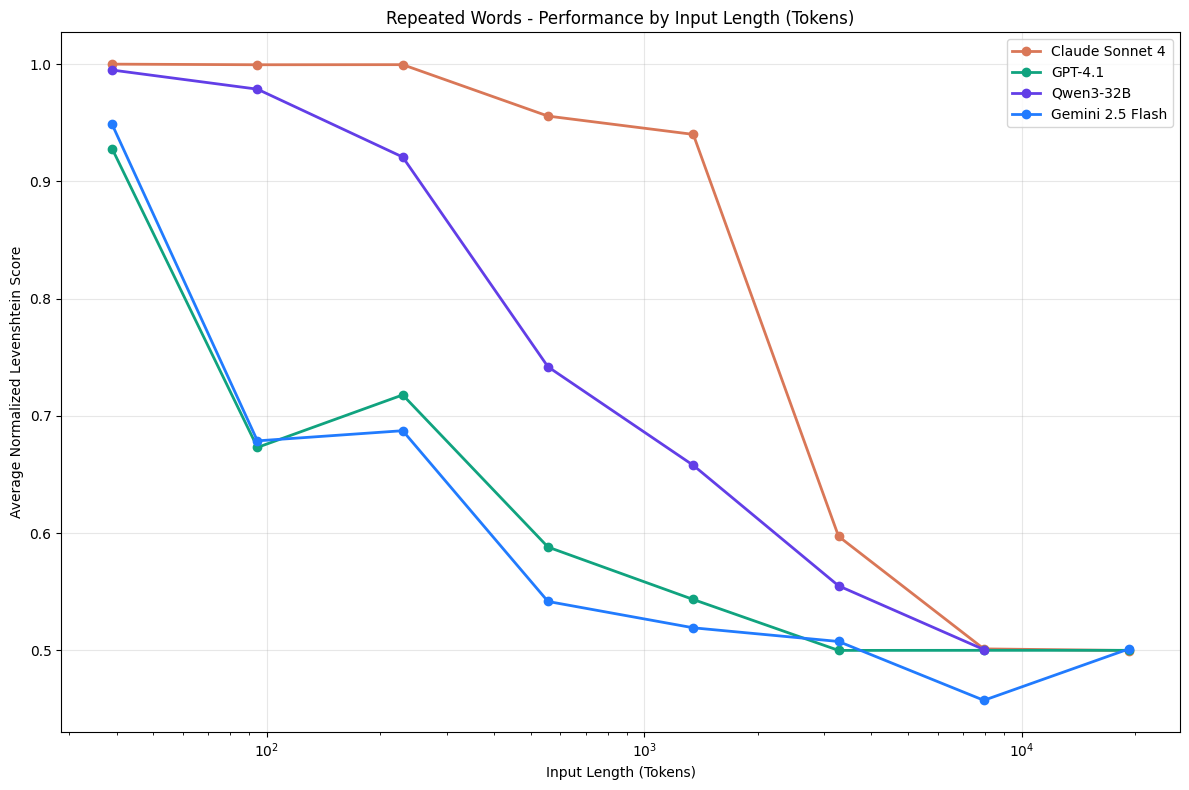
The phrase is newer than the problem. A commenter on Hacker News tossed out "context rot" in June 2025, and it caught on almost immediately. A month later the AI company Chroma put out a study that gave the idea some real weight. They ran 18 of the major models, including GPT-4.1, Claude Opus 4, and Gemini 2.5, and every last one got less reliable as the input grew. Even on simple tasks. And the slip started long before the context window was anywhere close to full. A model advertising a million-token window was already fumbling at 50,000.
A few things pile up to cause it. The big one is the "lost in the middle" effect. Models pay close attention to the start and the end of what you hand them, then sort of skim the part in between. Stanford researchers measured accuracy falling from around 75% down to 55% just by sliding the key fact into the middle of the text. The fact never moved out of reach. The model simply stopped weighting it. On top of that, every extra token is one more thing competing for the model's attention, so the useful bits get buried under noise. Andrej Karpathy has a good way of putting it. A context window is like RAM. It does not really remember anything. It just holds whatever is in view, and there is only so much room on the desk.
How context rot shows up:
- A long conversation that drifts, contradicts itself, or forgets something you said near the start.
- A coding agent that does great on a quick fix but comes apart on a long, multi-step job.
- A model that latches onto the wrong detail from early in a huge prompt and runs with it.
- Slower replies and bigger bills, since you pay for every token even when those tokens make the answer worse.
Context Rot Explained:
If you want the research behind the term rather than just the gist, the team that put context rot on the map walks through exactly how they tested it and what they found across all those models. It is a clear, surprisingly readable look at why feeding an AI more can quietly make it dumber.
FAQs
It is the steady drop in an AI model's answer quality as the amount of text you give it grows. The information it needs is usually still in there. The model just gets less reliable at finding and using it once the prompt gets long, which is why a long chat or a big document dump often produces worse results than a short, focused one.
A mix of things. Models attend well to the beginning and end of a prompt but skim the middle, so facts buried in the center get underweighted. Extra tokens also compete for a limited pool of attention, so noise crowds out the signal. And the longer the input, the more computing each new word takes, which is part of why quality and speed both fall off.
The usual fix is what people call context engineering, which mostly means feeding the model less but better. Keep only what is relevant to the current question, summarize long history into short notes instead of pasting it all back in, and start a fresh chat when the conversation shifts topics. Smaller, cleaner context beats a giant pile of it.