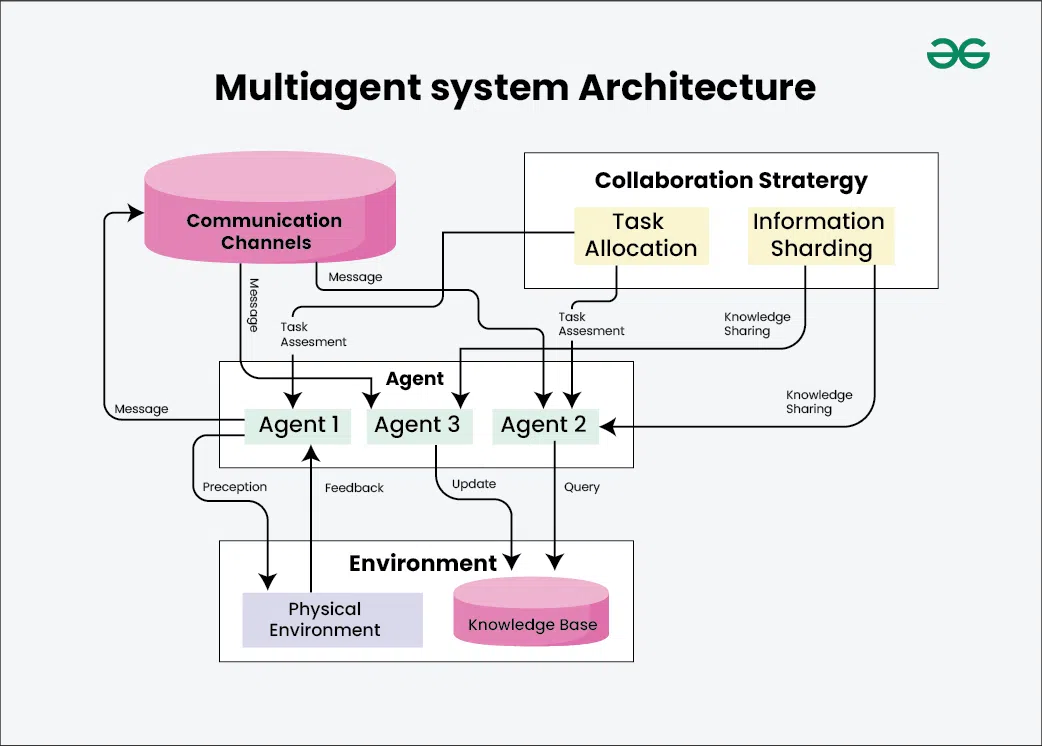
Model collapse is what happens when you train AI on the output of other AI, over and over, until the quality falls apart. Think of it like photocopying a photocopy. The first copy looks fine. The tenth is a smudgy mess. With AI, each new generation learns from the last one's output, small errors get baked in and passed along, and after enough rounds the model starts spitting out bland, repetitive, eventually nonsensical results.
The idea got its name and its proof from a 2024 study in Nature by Ilia Shumailov and his colleagues. They trained language models on data made by earlier versions of themselves and watched the quality slide with every generation. In one run, a model started on a normal passage about church towers and, a few generations later, was rambling about jackrabbits. The researchers called the damage "irreversible." The internet, never shy with a nickname, started calling it Habsburg AI and AI inbreeding.
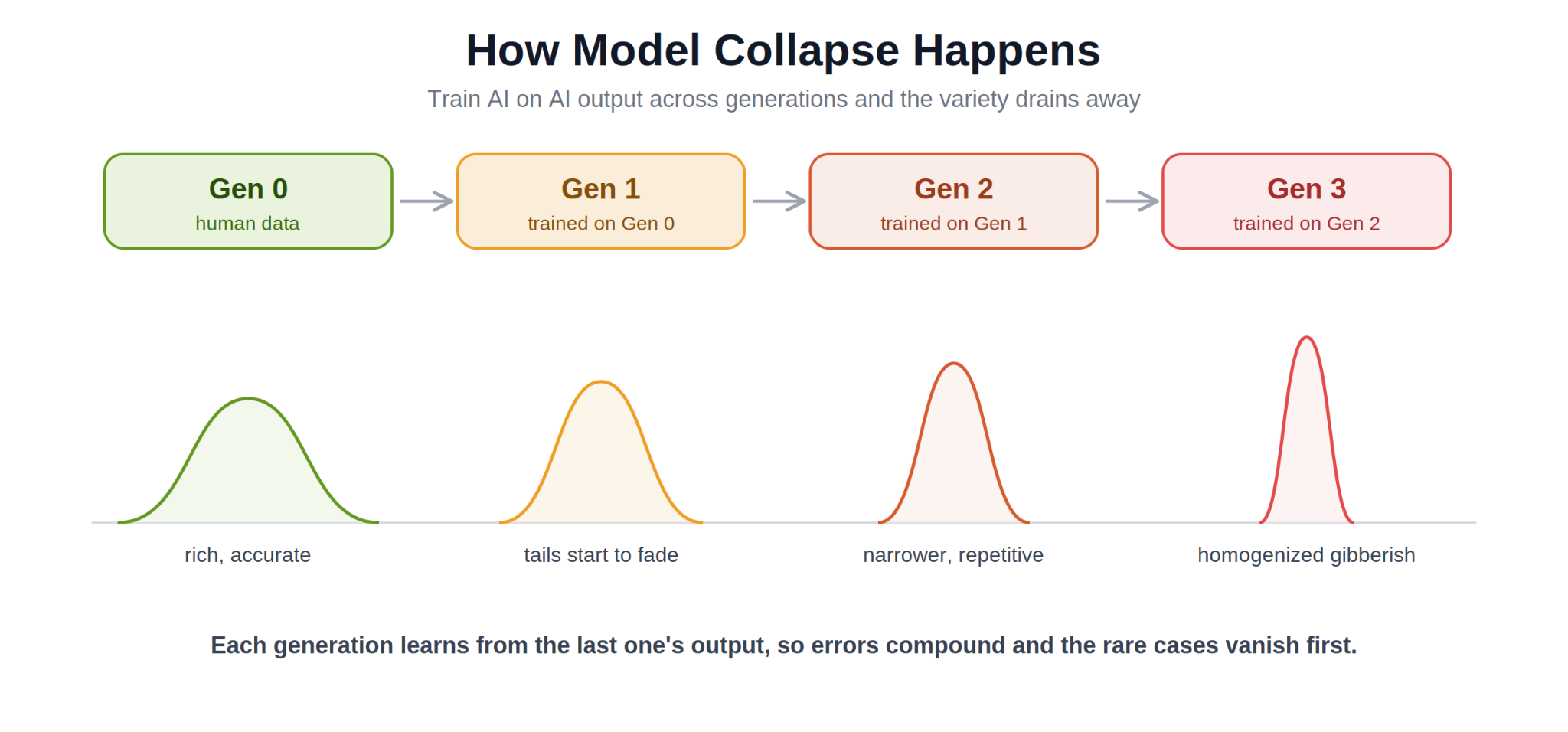
Here is the part that matters most. The first thing to go is the rare stuff. AI tends to favor the common, high-probability words and ideas, so the unusual ones, the edge cases, the minority voices, fade out first. That is why early collapse is sneaky. The model can look like it is doing fine on average while it quietly loses everything at the margins. Keep going and the output collapses toward a narrow, samey middle with no surprises left in it.
There is a real reason people worry about this beyond one lab experiment. As AI slop piles up across the web, the next round of models gets trained on a web that is partly AI already. Some researchers think that loop could degrade the whole field over time, which is part of why clean, pre-2023 human data has become so valuable. Worth being fair, though, this is debated. Other researchers argue that as long as fresh human data keeps getting added alongside the synthetic stuff, instead of replacing it, collapse is mostly avoidable, and the doomier predictions are overblown.
Why model collapse happens:
- Errors compound. Each generation inherits the last one's mistakes and adds its own on top.
- The tails vanish first. Rare words, edge cases, and minority data get dropped before anything else.
- Outputs homogenize. Variety shrinks until the model keeps returning the same safe, average answers.
- The web gets polluted. AI content online ends up in the next training set, feeding the loop.
Model Collapse Explained:
Want to go a level deeper on the problem and the fixes? This Super Data Science episode walks through what generative AI model collapse actually is, why it sets in once models start training on each other's output, and what researchers think might stop it.
FAQs
Model collapse is the gradual breakdown of generative AI models that are trained on AI-generated data. As each new model learns from the output of older ones, errors stack up and the variety in the data shrinks, so the results get less accurate and more repetitive over time, eventually turning into junk. It was formally described in a 2024 Nature study.
It comes from a feedback loop. When a model trains on content made by other models instead of real human data, it slowly drifts away from how the real world actually looks. The rare, low-probability cases disappear first, then the output narrows toward a bland average, and the mistakes from one generation get passed into the next and amplified.
There are a few defenses. Keep real human data in the training mix instead of letting synthetic data take over, track where data came from so AI content can be filtered out, and hold on to clean datasets from before AI flooded the web. Some researchers also point out that if human and AI data simply accumulate together over time, the worst of the collapse may not happen at all.