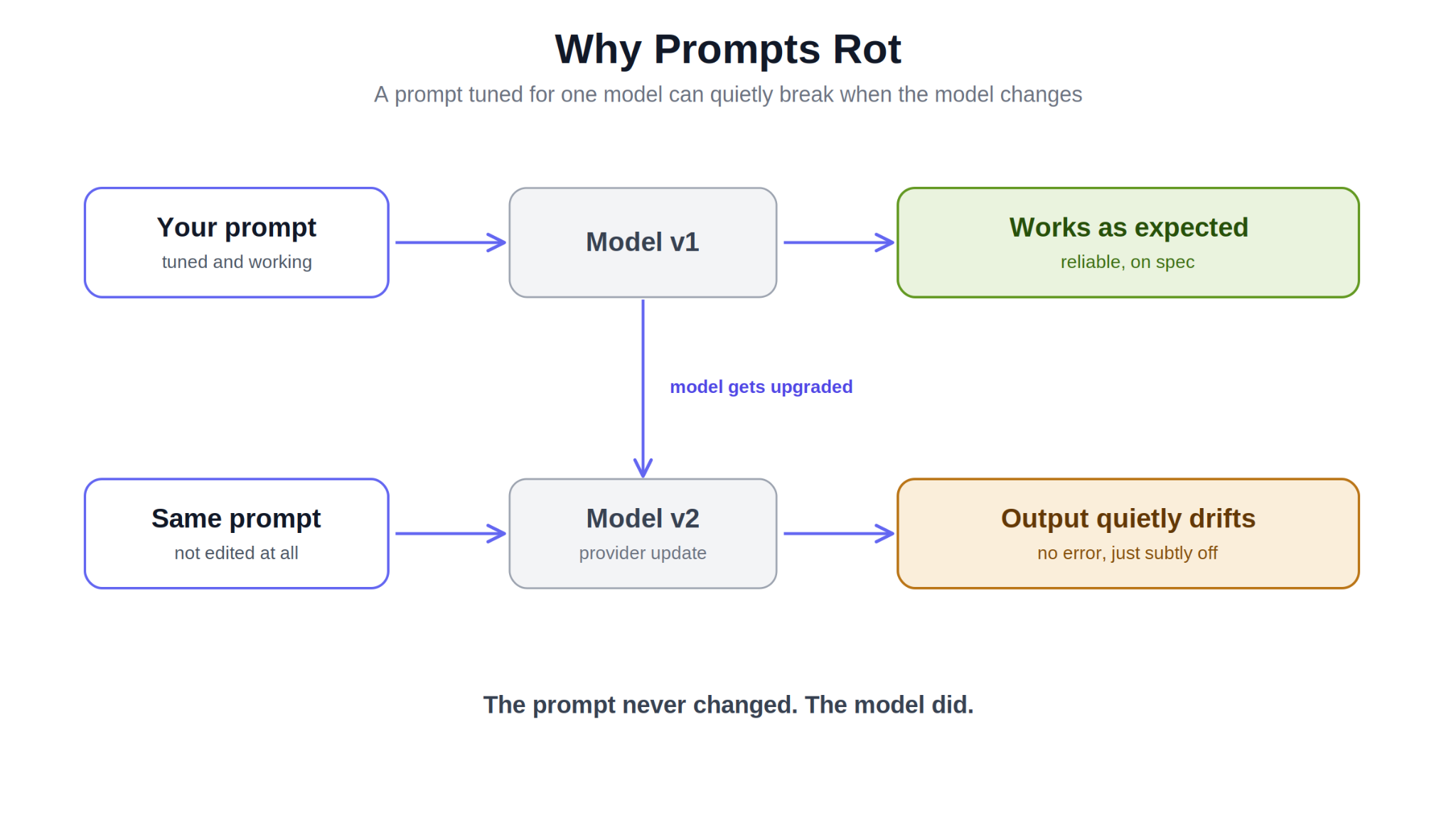
Prompt rot is when a prompt that used to work just fine slowly stops pulling its weight. Nothing crashes. No error pops up. The answers just start landing a little off, and one day you realize the thing you relied on is not as reliable as it was. Most of the time the cause is not your prompt at all. It is the model underneath it changing while the prompt sits still. This is closely related to context rot, but it is its own problem, and worth knowing apart.
Here is what is actually going on. When you spend time tuning a prompt, adding examples, tweaking the wording, getting the order just right, you are not only telling the model what you want. You are quietly shaping how that specific version of the model responds. So when the provider ships an update, or you swap to a newer model to save money, the ground shifts. The prompt is the same to the letter. The model reading it is not. What looked like rock-solid prompting was really a private handshake with the old model, and the new one never agreed to it.
The tricky part is how quiet it is. Prompt rot almost never breaks loudly. The output still reads fine at a glance, so people blame randomness, or temperature, or a bad day, and miss that the model moved under them. Few-shot examples are especially prone to this. A set of examples that locked in good behavior on one model can nudge a newer model in a slightly wrong direction without anyone noticing for weeks.
There is a second way people use the term, more about buildup than model changes. In that version, a long-running AI agent rots because teams keep bolting on fixes. One workaround for this edge case, another for that one, a correction here, a special rule there. Each patch makes sense by itself. Stacked up over months, they start to contradict each other, the original intent gets buried, and the agent drifts. Same name, different root cause, and the fix is mostly discipline, like trimming the prompt regularly instead of only ever adding to it.
Common ways prompt rot creeps in:
- Model updates. The provider ships a new version and your untouched prompt quietly behaves differently.
- Switching models. Moving to a cheaper or newer model carries over a prompt that was tuned for the old one.
- Overfit few-shot examples. Examples that anchored behavior on one model steer the next one slightly wrong.
- Patch pileup. Months of small fixes and special cases bury the original intent until the prompt contradicts itself.
Prompt Engineering, Explained:
Prompt rot is really a prompt engineering problem, so it helps to see where prompt engineering ends and context engineering begins. In this explainer, IBM's Martin Keen breaks down the difference and shows how the two work together to keep AI output reliable.
FAQs
Prompt rot is when a prompt that used to work well gradually produces worse results, usually because the model behind it changed. The prompt itself stays the same, but a model update or a switch to a different model shifts how that prompt gets interpreted, so the output quietly drifts off target.
Mostly because a tuned prompt is secretly fitted to one specific model. The examples and phrasing that shaped good behavior were really an undocumented deal with that model version. Update or swap the model and the deal is off, even though not a word of the prompt changed. A second cause is buildup, where months of patches and edge-case fixes pile onto an agent until they start to conflict.
You cannot kill it off entirely, but you can slow it down. Lean on clear, explicit instructions instead of relying on the model to infer patterns. Use few-shot examples to show intent, not to hard-code rules. Where you can, enforce strict requirements outside the prompt, like validating the output in code. And revalidate your prompts whenever the model changes, the same way you would retest code after an upgrade.