












 Instagram
Instagram  X (Twitter)
X (Twitter)  Youtube
Youtube 











Large Language Models (LLMs) have changed the way businesses approach knowledge management, sales enablement, workflow automation, and employee training. They’re quick, flexible, and, let’s be honest, can sound a lot like humans.
But they’re not perfect. Not by a long shot.
Those of us who experimented with ChatGPT in the beginning will remember that math wasn’t exactly a strong suit.
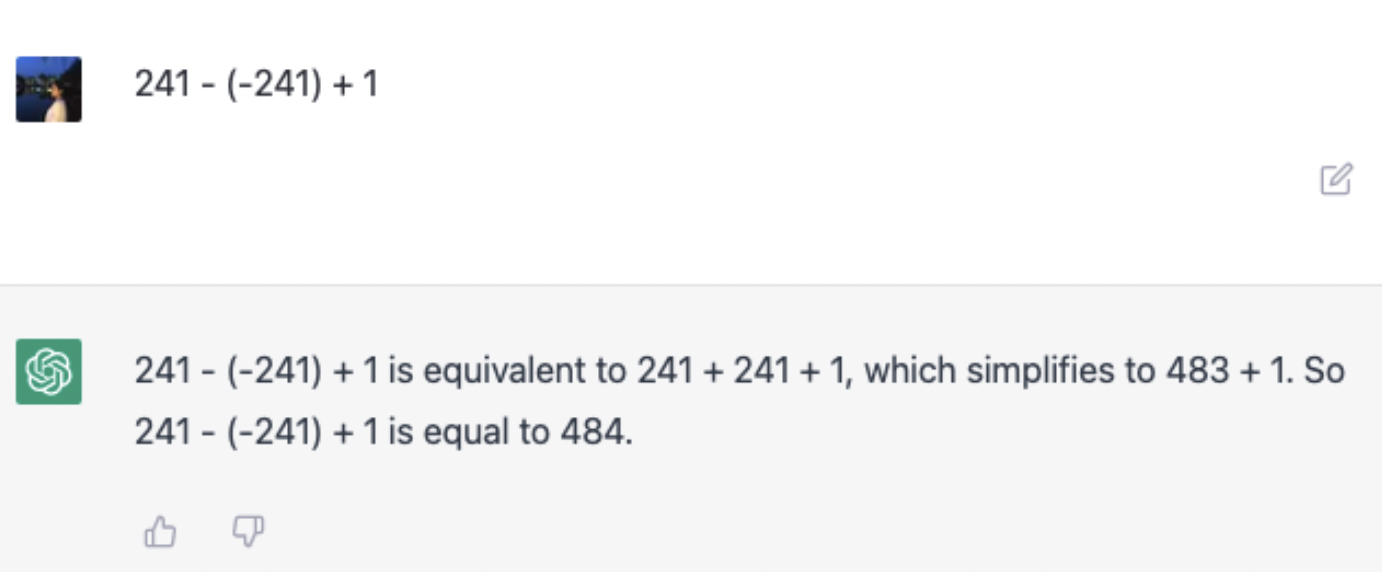
And who can forget the infamous strawberry debacle?
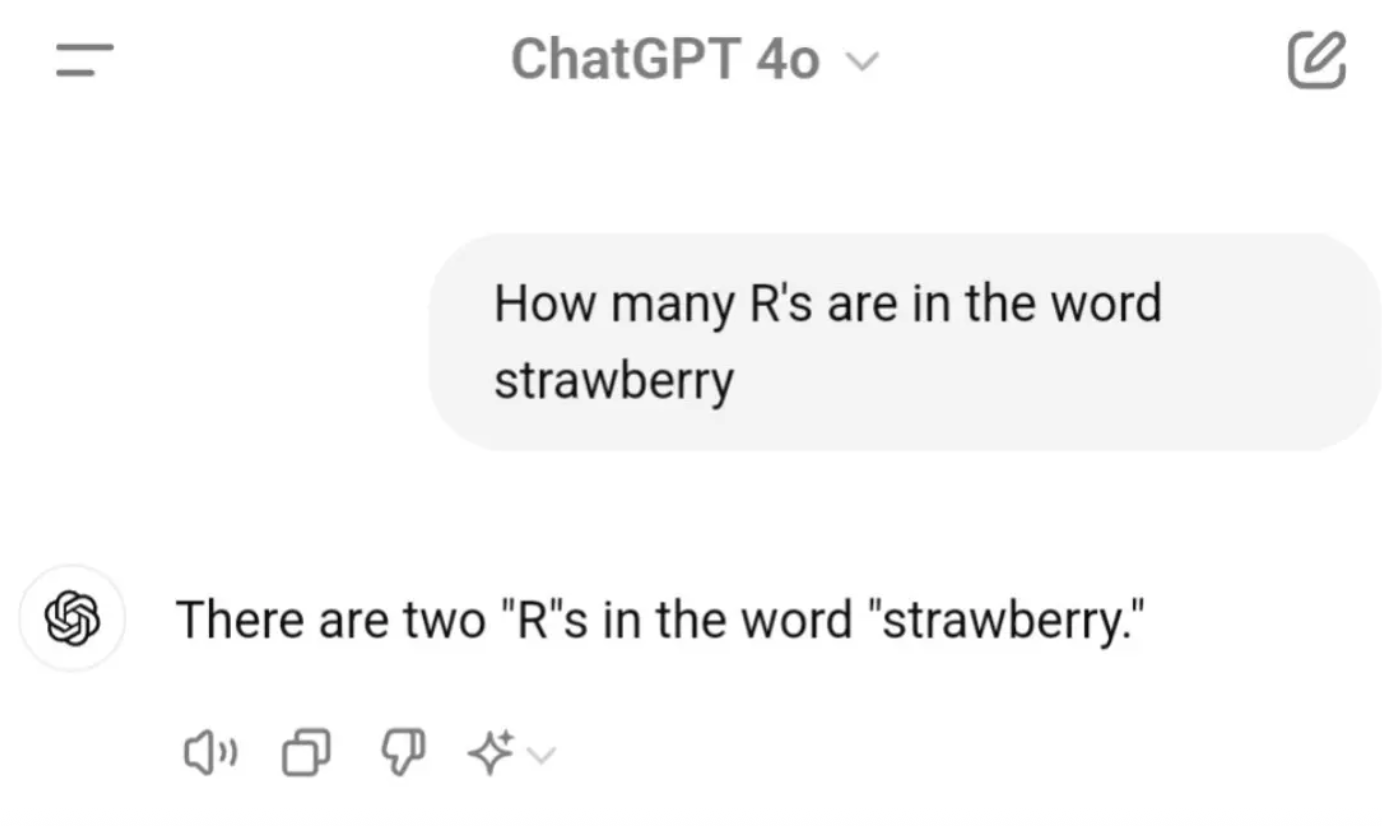
Of course, LLMs have come a long way since those early fumbles.
Still, there’s one big point of failure LLMs have not quite overcome: they’re really bad at knowing how right (or horribly wrong) they are.
Some vendors call this ability confidence scoring. This refers to a model’s ability to assign a level of certainty to its answer.
But asking an LLM to rate its own output is like asking a high school student to grade their own test without the answer key.
It’s just not realistic.
Key Takeaways
- LLMs are not calibrated to evaluate whether their answers are correct.
- Fluency does not equate accuracy. Don’t be fooled by how convincing an answer sounds just because the model speaks confidently about a topic.
- Confidence scoring is best handled by external systems, not the model itself.
Here’s why LLMs fail at confidence scoring:
1. No Built-In Calibration
Before we dive into this, you should understand what exactly is a token – a token is a fundamental unit of text that the LLM processes.
LLMs are trained to predict the next word. They don’t, however, assess whether or not that word (or sentence or paragraph) is correct. Internally, models will assign probabilities to each token they generate, but that obviously won’t ensure accuracy.
As an example:
- A token with a high probability isn’t guaranteed to be correct.
- A token with low probability isn’t necessarily wrong.
These token-level probabilities are basically getting to the heart of what sounds right. This decision is based on training data. They reflect statistical patterns in language, not factual correctness. They’re derived from the model’s training data and help predict what word or token is likely to come next.
Models like Word2Vec generate word embeddings that capture relationships between words in vector space, not probabilities. Transformer-based models such as GPT-4o weigh contextual relevance to figure out token probabilities.
What they do not, and cannot provide, is a real sense of truth.
In other words, LLMs aren’t calibrated like a weather forecast.
Rather, they’re like a parrot repeating what they’ve already heard, with confidence.
When you’re asking the AI to present a confidence score, you’re asking it to grade its own answer. How does that make sense? If the AI thought it was a bad answer then it probably wouldn’t have generated it in the first place. You would need a completely separate entity (human or otherwise) to determine the true quality of a response.
George Avetisov, Founder @ 1up
2. Overconfidence and Fluency Bias
What’s a classic LLM trap?
The answer sounds so good, so it must be right.
Well, it’s maybe sort of probably wrong.
LLMs are optimized for fluency. They generate coherent, natural-sounding text.
This typically means you’ll get:
- Fluent but incorrect answers, which is why it sounds so good.
- Lack of natural hedging (“I think…” or “This might be…”), unless you explicitly ask for it.
- Overconfidence, even when the model is taking a wild guess, which, again, is why it sounds so good.
These responses create a dangerous illusion of accuracy. Particularly with sales, customer support, or compliance, sounding right is not enough. In fact, it’s worse than no answer at all if it’s wrong.
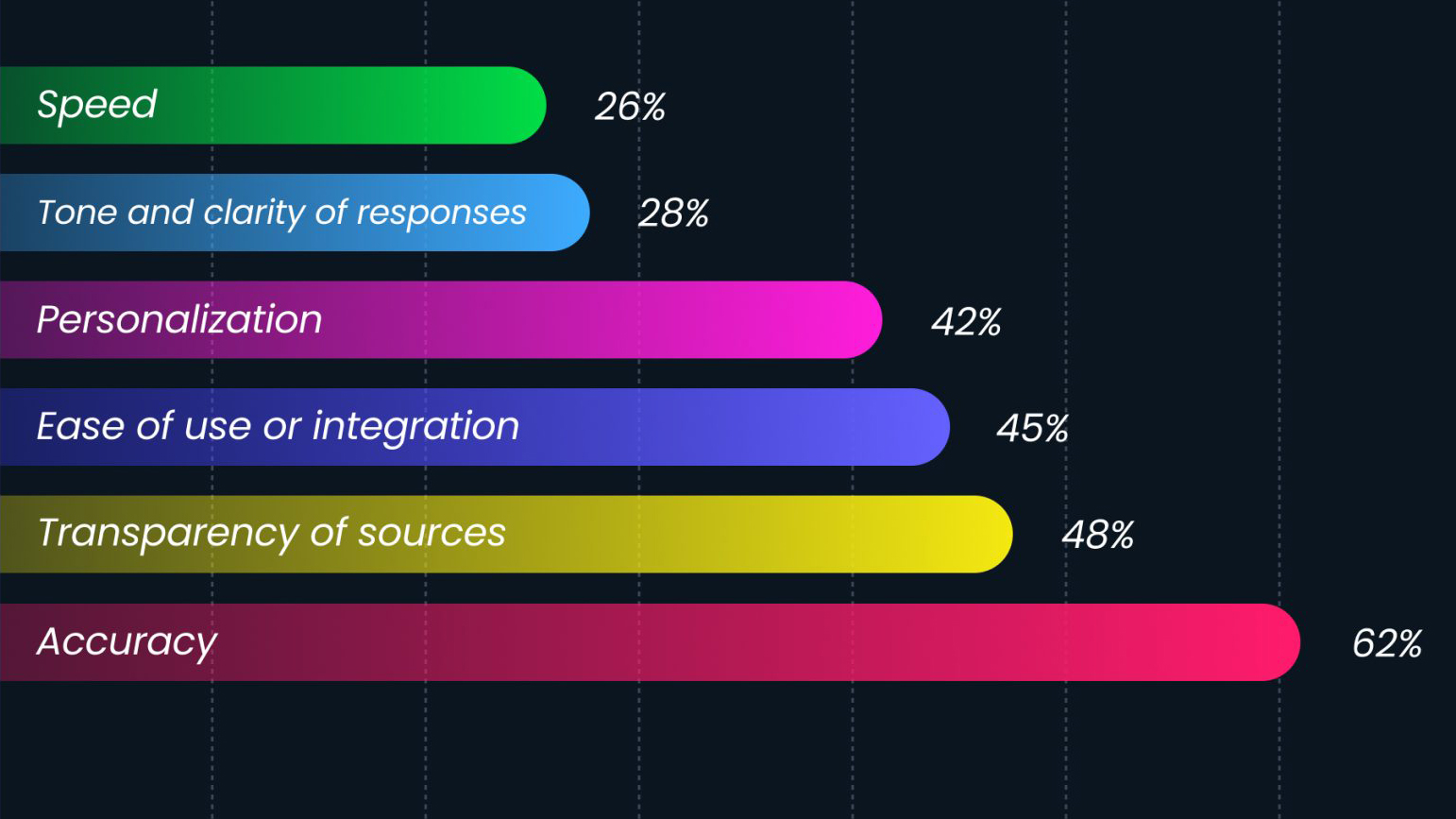
We ran a test of multiple vendors who advertise Confidence Scoring. We found that pretty much any response scored below 80% was unusable.
Ed Poon, Founder & CTO @ 1up
Users tell us that they prefer to see AI-generated responses in a binary state. A query is either answered or it isn’t. Asking a model to score this gray area only further reduces confidence.
3. No Ground Truth Awareness
LLMs do not know whether an answer is factual. They lack a mechanism to verify outputs against a grounded truth (like a human checking their work against an encyclopedia).
Unless they’re explicitly designed to test against an external knowledge system, they won’t actually know if a response is grounded in reality. At best, models are pulling blindly from the most highly rated information on the vast world of the web. At worst, they’re relying entirely on their training data which may be outdated or incorrect.
It is here that Retrieval-Augmented Generation (RAG) systems play a crucial role.
RAG systems pull in information from a knowledge base, which gives the model a “source of truth.”
- It grounds responses in real documents, which improves the level of factuality.
- It enables specific source citations, so your team can always verify answers.
- It supports response auditing, wherein a verifier model (or human) can double-check if the answer matches retrieved data.
Still, even with a RAG-based system, if you ask it to grade itself, you’re right back to where you started. You’re still asking the model to self-assess… and that’s just not going to work.

4. Training Objective Misalignment
LLMs aren’t trained to know when they’re wrong.
The primary objective of most Language Models is to minimize next-token prediction loss. This means they’re rewarded for generating plausible continuations of text.
But they’re not rewarded for:
- Admitting when they don’t know something or aren’t sure.
- Choosing silence over speculation, so they always come up with something… anything.
- Assigning useful, human-readable probabilities to their own accuracy.

The model gets no bonus points for saying, “You know what… I’m not sure.” So it won’t say that.
Even the latest models like still suffer from this kind of mismatching. Sure, they’re getting better at saying, “I’m uncertain.” But that’s usually because the user has prompted the model to do so. Or, they might have been exposed to examples of hedging, so they know how to mimic it.
5. Token-Level vs. Answer-Level Uncertainty
Okay, let’s say a model generates a 100-word answer.
Just because it assigns individual probabilities to each token, that doesn’t mean we can average those to get a single “confidence score” for the whole response.
Why?
- The relationship between token confidence and answer-level accuracy is nonlinear.
- High token fluency doesn’t mean high factual reliability.
- Important factual errors can be hidden in low-entropy language.
What this means is that token-level confidence (which is what LLMs expose) doesn’t help much when we need to know whether the entire answer is reliable.
That last part is still subjective.
Without Confidence Scoring, How Can We Improve AI Outputs?
Right. So what can we do instead? Since we can’t trust LLMs to grade themselves (and we’ve established we can’t), we need to mix machine-level and human-level solutions to bridge the gap.
Machine-Level Improvements
- Post-hoc calibration models: Train a separate classifier to predict whether an LLM’s answer is correct based on:
- Token entropy is the amount of uncertainty or randomness present within a token.
- Prompt-answer overlap – the degree to which the generated answer mirrors language from the original prompt. This may signal overfitting or a lack of reasoning.
- RAG + verifier: Use retrieval-augmented generation with a separate verifier model to score output reliability. Then, if the verifier finds inconsistencies, it will flag the response as low-confidence.
- Fine-tuning for uncertainty: New research is fine-tuning LLMs, so they’ll say “I don’t know” when they get an ambiguous prompt or they find conflicting context. This is still in the experimental stages, but so far the results are promising.
Human-Level Improvements
Get Humans to Grade AI Outputs: They can use a simple thumbs-up or down rating to collect human feedback. These labels help calibrate the model over time.

Offer Answer Choices: Give humans options to choose from. For example, you can see how LLMs give multiple answers to a single query and let humans choose the better one. This feature gives optionality, and it reinforces to the model what “better” looks like.

Let Users Correct the Model: Give users a way to make the answer better themselves in real-time. This real-time correction loop turns users into active trainers. It also helps the model learn from its mistakes.

In the End: Don’t Ask AI to Grade Itself
Yes. We know. LLMs are great for generating content, summarizing knowledge, and accelerating work across departments.
But we also know that they’re fundamentally not evaluators of their own outputs.
With confidence scoring, you need:
- External validators (human or machine)
- Better feedback loops
- Architecture-level changes if you expect the models to say “I’m not sure.”
Until we get to that point, you need to treat every answer that sounds confident with healthy skepticism. And always, always, always make sure there’s a path for validation, correction, or improvement.
See how 1up enables answers grounded in reality
Try 1up for free and experience how sales teams get fast, accurate answers to technical questions.








![The State of AI in Knowledge Management [2026]](https://1up.ai/wp-content/uploads/vhs_cassette_state_of_ai_in_knowledge_1.png)